让大模型歇一歇,让Agent上
在需要大模型调用大量工具的场景定义一套DSL,大模型只需要生成一系列语句来表达一个复杂的任务,由Agent来执行这些语句从而避免让大模型调用大量工具,这样既提高了性能,又获得了稳定执行的效果,还节省了tokens,这就是我给工作流里任务编排设计的方案。
这套方案不仅适用于工作流,还适用于所有能支持DSL的场景。
下面我来讲讲这套方案是怎么设计出来的。
首先,传统的Agent架构大体上是这样设计的:
用户输入需求,大模型利用推理能力判断决定调用哪个工具,Agent替大模型调用工具后将结果返回给大模型,大模型决定下一步是否继续调用工具,需要的话继续上面的步骤,不需要的话输出一段结果给Agent,Agent判断当前轮次结束,展示大模型输出结果后等待用户再次输入。
Agent设计的目的就是替大模型干活,这也是Agent这个词的本来含义:代理。
Claude Code是这样设计的,OpenCode、Cursor等有名的编程Agent都是这个架构。
所以很多人说:Agent的架构一点也不复杂,里面也没有多大技术含量。
话说的虽然没错,但我们还想问一问:Agent的架构只能有这一种吗?Agent就只能用来帮大模型调工具吗?
大模型调用完多轮工具后输出结果就会停下来等待用户输入,这本质上还是AI聊天工具的设计逻辑,是一种chat runner。
让chat runner跳出聊天,去面对更多场景的时候总觉得跟它的聊天架构有些冲突有些别扭。
比如,大模型调用工具会存在一些问题:
- 每次工具调用结果都需要回传大模型,需要反复请求,效率很低,tokens却很费
- 整个过程都需要由大模型来控制,调用工具多了上下文持续增长时大模型容易有注意力漂移、产生幻觉,越跑越偏的风险。
- 由于上下文的限制,如果工具调用的结果很长,往往只能截断后再给大模型,容易缺失信息。
在我们Agent特区(https://www.agentszone.ai/)的讨论群里,有人说,那是因为你给大模型的任务颗粒度不够细,大模型完成小颗粒度的任务是很准确的,只能怪你不会拆任务,不要怨我们亲爱的大模型。
这话听着在夸大模型,实际上在暗示它没能力完成复杂的任务,明褒实贬啊。
但他说得其实有一定的道理,大模型执行任务时本质上是在一个空间中求解,当任务的复杂度太高时,解的空间也变大了,大模型在一个过大的空间中求解时出错的概率也就跟着变高了。
这也是为什么一些SDD框架比如BMAD要将用户的需求先拆成多个story,多个epic了,将颗粒度拆细了才能提高大模型的准确率。
但是,即使任务能拆细,当拆得足够多时,怎么编排这些任务又成了问题。
编排难题
我们以研发工作流为例来进行说明,很多研发工作流的过程是这样的:
- 大模型理解用户需求大模型生成开发计划。
- 比如拆分原子任务、制定验收标准等,生成了多个任务。
- 大模型决定逐个执行任务。
- 大模型收到任务执行完通知决定验收。
- 大模型发现验收不通过决定执行修复动作。
- 大模型最终判断所有任务都执行完了高兴地向用户汇报。
大模型在执行每一个子任务时大都没什么毛病,问题出在这整个工作流程的推进和控制上,很多人都碰到过类似问题:
- 大模型执行了几个任务后突然停下来了。
- 大模型执行过程中漏掉了一个任务。
- 大模型把两个任务顺序搞反了等等。
为什么会这样呢?
因为大模型在控制任务的编排时本质上还是靠的工具调用,比如任务拆完了可能会调用todoWrite来记录任务,收到todoWrite结果后又会开始调用下一个工具。
每个任务都是一堆工具调用,每次工具调用后都要重新做一次判断:下一步该干嘛,要继续调用下一个工具还是停止?当前任务是否已结束等等。
所以,大模型编排任务的过程很不符合直觉:明明任务都规划好了,但它每调用一次工具都要重新判断一次下一步究竟要干啥?
这是因为大模型内部是没有记忆的,它不知道任务早就规划好了,也不记得刚刚调用了什么工具,它忘却了初心。
大模型每次都只能根据请求里的信息重新理解一遍前面都做了哪些事,调用了多少工具,每次都要重新推理判断,每次的判断都有小概率会出错。
如果调用了上百次工具,就要做上百次的回顾、判断,可怕吧?
不仅如此,每调用一次工具都会收到一次调用结果,有大量的工具调用就会有大量的调用结果,这些结果都会附加到会话里,使上下文会变得越来越长,这就又回到了我们上面提到过的问题:大模型的注意力开始漂移,它疲劳了。
所以长程任务的持续执行一直是大模型的难点。
各家模型几乎都在大模型长时间稳定调用工具方面做了很多训练,这也反过来说明它的难度之大。
有没有别的方案呢?
特别是,有没有符合我们直觉的方案:任务规划好了,就按规划逐个推进,不用每次都重新判断呢?
答案是让程序来做,不依赖大模型。
要知道如果想稳定地执行计划,程序才是最佳的选择,因为程序没有自己的心思,它只会按事先定义好的规则来执行。
传统的Agent设计思路都是围绕着怎么协助大模型调用好工具,怎么给大模型提供足够的环境信息等等,都是围绕着怎么服务好大模型在设计。
但是,程序本身也可以主动做一些事,无需事事麻烦大模型,可以让大模型也歇一歇。
我们完全可以打破Agent架构设计的思维惯性,不要只把Agent仅仅当成工具调用的代理,不要局限于它的名称,不要事事都去问大模型靠大模型决策。
具体怎么做呢?
什么时候让大模型做判断做决策什么时候又交由程序来主动上呢?
这需要一套大模型与程序之间的协议,大模型按照协议输出,程序根据协议判断下一步还需要麻烦大模型还是说该自己主动上了。
比如,当大模型拆分好任务后可以以数组形式输出任务列表,Agent识别到这种数组就采用最简单的程序遍历,逐个提取数组中的任务执行,最后将所有执行结果返回给大模型就够了。
整个过程是程序在控制着任务的编排执行,大模型再也不用不停地调用工具然后判断该不该继续,下一步该干嘛了,会话上下文也不会堆积反而更干净了。
当然,程序在执行具体任务时仍然是调用大模型,每个具体的任务可以使用一个单独的会话,调用相匹配的Agent来执行,这样不但能并行,还做到了天然的上下文隔离。
任务也不一定要用数组来表示,对于复杂一点的任务编排,可以让大模型生成一个workflow,程序按照workflow来控制运行。
如果是workflow,那这套协议,本质上就是一套DSL,让大模型按照DSL的规范来生成workflow,下面是用json格式来展示的一个例子:
{
"id": "wf_20260517_103012_a8f3",
"schema": 1,
"goal": "Fix SDK generation and verify the result.",
"status": "running",
"created_at": "2026-05-17T10:30:12Z",
"updated_at": "2026-05-17T10:35:00Z",
"assumptions": [
"The JavaScript SDK is regenerated by packages/sdk/js/script/build.ts.",
"Typecheck is the minimum verification gate."
],
"success_criteria": [
"The requested code change is implemented.",
"The SDK is regenerated when API shapes changed.",
"Relevant package typechecks pass."
],
"nodes": [
{
"id": "research",
"type": "research",
"title": "Inspect SDK generation flow",
"file": "nodes/research.json",
"depends_on": []
},
{
"id": "implement",
"type": "implementation",
"title": "Apply the code change",
"file": "nodes/implement.json",
"depends_on": ["research"]
},
{
"id": "test",
"type": "test",
"title": "Verify the change",
"file": "nodes/test.json",
"depends_on": ["implement"]
},
{
"id": "review",
"type": "review",
"title": "Review implementation and verification",
"file": "nodes/review.json",
"depends_on": ["test"]
},
{
"id": "gate",
"type": "gate",
"title": "Accept workflow result",
"file": "nodes/gate.json",
"depends_on": ["review"]
}
],
"policies": {
"on_node_failed": "ask_decision",
"on_blocked": "ask_decision",
"max_attempts": 2
}
}DSL不是只能有一套,在不同的领域可以设计不同的DSL,让大模型生成workflow再设计专用的Agent来执行。
这一类Agent也不再是chat runner,而是workflow runner,你也可以设计其他类型的runner,总之思路不要局限于聊天工具。
如果你面对的场景适合定义一套DSL,那么就可以考虑用类似的方式来实现你的Agent。
比如如果要开发一个Agent协助用户去操作一个系统,可以将系统可操作的元素、步骤定义成一套DSL,让大模型根据需求和DSL定义生成一个workflow,这比传统的做法每操作一个步骤都回传给大模型判断推理一次要高效和稳定得多。
像低代码领域这种本来就有DSL的场景,也可以考虑类似设计。
当然,并不是定义一套DSL,每次让大模型去生成workflow让程序执行就万事大吉了。
哪些部分交给大模型,哪些交给Agent程序本身,大模型与Agent之间如何交互等等,都需要根据实际场景好好设计。
下面是我利用Agent程序执行workflow的一个实验:
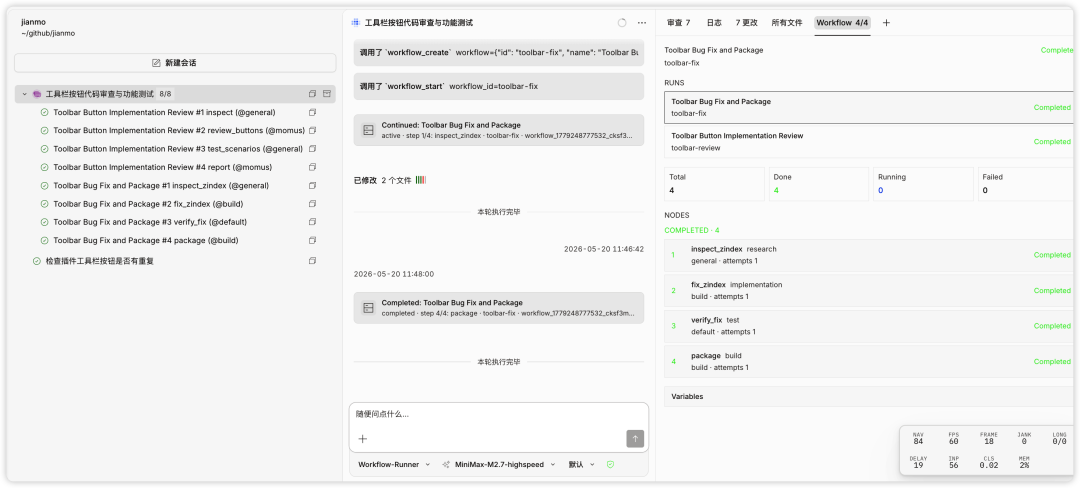
实验完后发现,主会话总共只有6次工具调用,实在是太省了。

这么节省的方案,谁能不爱呢?