toolCall一直在拖Agent的后腿
LLM Agent 的基本运行逻辑
toolCall机制在LLM Agent执行复杂任务中起着关键作用,模型要读文件、查资料、跑命令、调 API等等等等,都离不开toolCall。
所以,可以说toolCall是Agent的核心,是灵魂,今天的Agent 的运行逻辑基本上都是建立在 toolCall loop 上。
但是,Anthropic 在《Introducing advanced tool use on the Claude Developer Platform》这篇文章中也提到,tool calling 在复杂工作流中会遇到两个问题:
- 中间结果污染上下文。
- 每次工具调用都需要一次完整模型推理。
文章里给过一组数据:
工具定义和工具结果有时会在 agent 读到用户请求前就消耗 50,000+ tokens;
内部场景里工具定义优化前甚至消耗过 134K tokens。
为什么会这样?
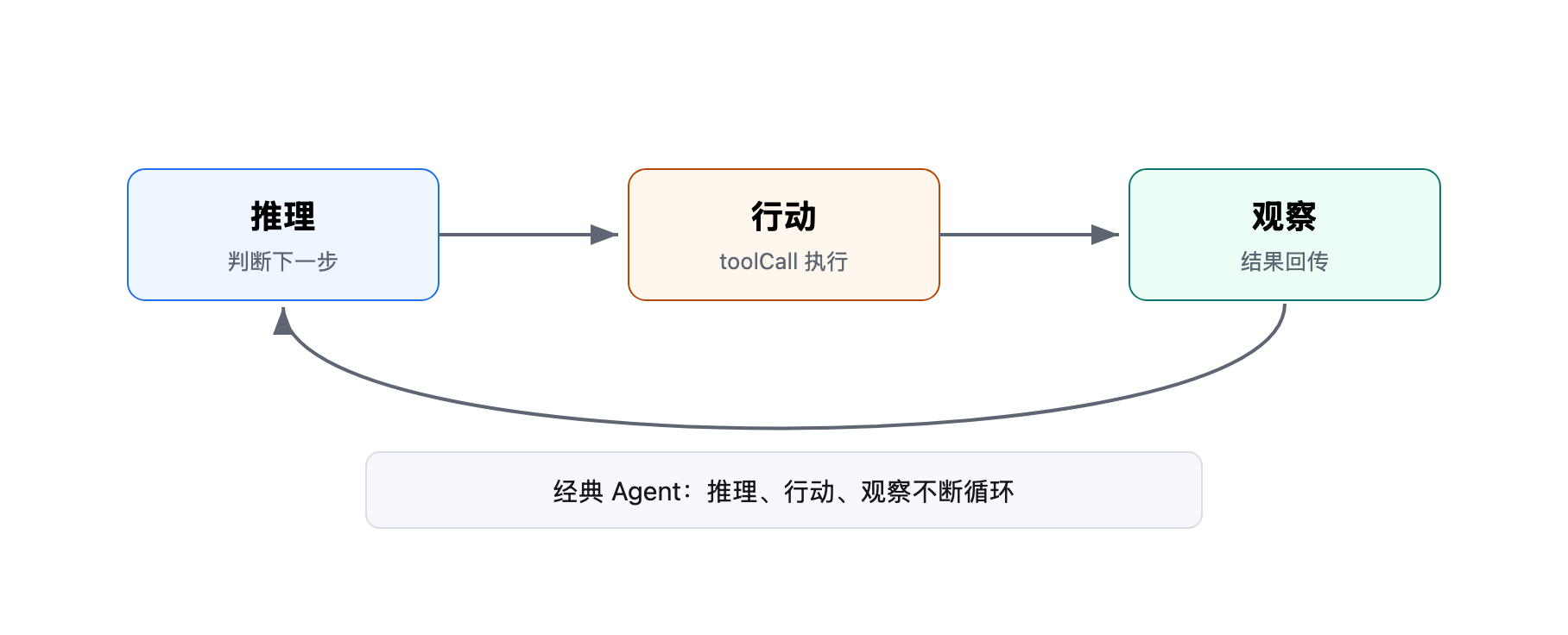
我们先回到LLM Agent 的设计思路,一般都可以简单概括为推理、行动、观察三者循环。
其中行动都需要靠调用工具来完成,也就是 toolCall,工具调用结果作为观察返回给模型,模型再进入下一轮推理。
模型会根据工具调用结果判断下一步该干嘛:是继续调用工具还是结束当前会话。
推理、行动、观察循环这个设计本身没什么问题,甚至可以说简洁优雅,小小的结构能产生巨大的威力。
问题在于,toolCall 这个机制与大模型本身的特性不是那么匹配。
toolCall 的问题
大模型本身是没有记忆的,所以它不记得之前调用过什么工具,有过什么结果,因此,每次请求大模型时都要将前面调用过的所有工具和相应结果都原样输入一次来供大模型进行推理。
而工具调用本身通常是非常细的动作,大模型要完成一个任务往往不止调用一个工具,而是要调用一系列工具,有时甚至要调用上百次工具。
每次工具调用的结果大小往往又不确定,有大有小,有可能是读取一个文件结果有一大段内容,也有可能是查找文件一个都没查到。
这就造成了当工具调用次数多的时候,提交给大模型的请求里就包含了大量的工具调用记录和结果记录。
而这些记录并不都是精确围绕大模型所要完成的任务相关的,有很多无关的或相去甚远的内容,这就会影响大模型的识别推理。
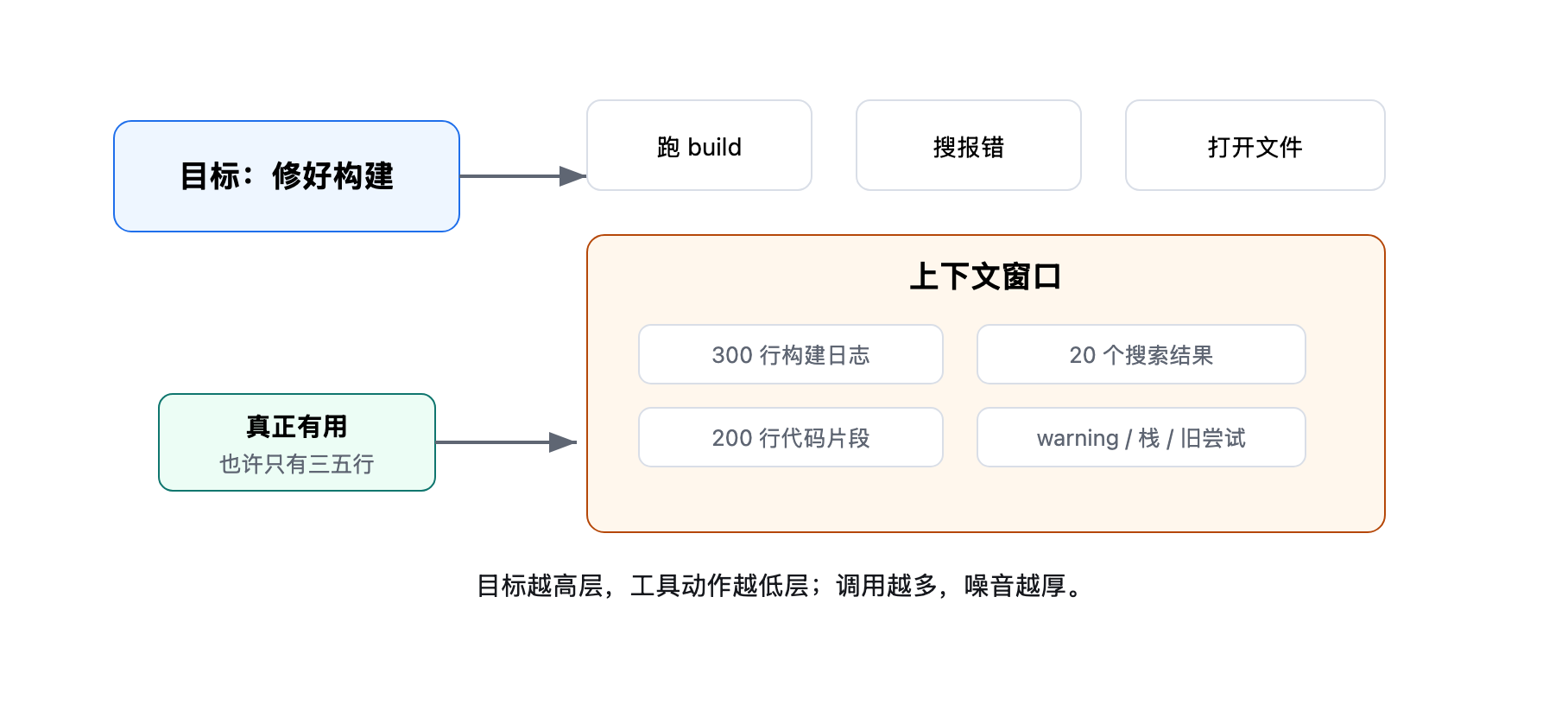
比如目标是“修好构建失败”,第一次 build 返回 300 行日志,第二次搜索返回 20 个匹配文件,第三次打开文件又带回 200 行代码,第四次测试再产生新的失败输出。
真正有用的信息可能只有三五行,但模型要在一整堆局部材料里继续推理,那些无用的信息占比过大会干扰大模型,成了噪音。
工具调用越多,对大模型的干扰就越容易变得严重,所以各家大模型厂商都在大量工具调用上下了苦工夫,也吃够了苦头。
所以上面Anthropic就提出了,用一种 Programmatic Tool Calling的新方案来进行工具调用,来缓解这个问题。
ReAct、LangGraph、AutoGen 的解法
不止Anthropic,业界有好几个框架都在试图来解决这个问题。
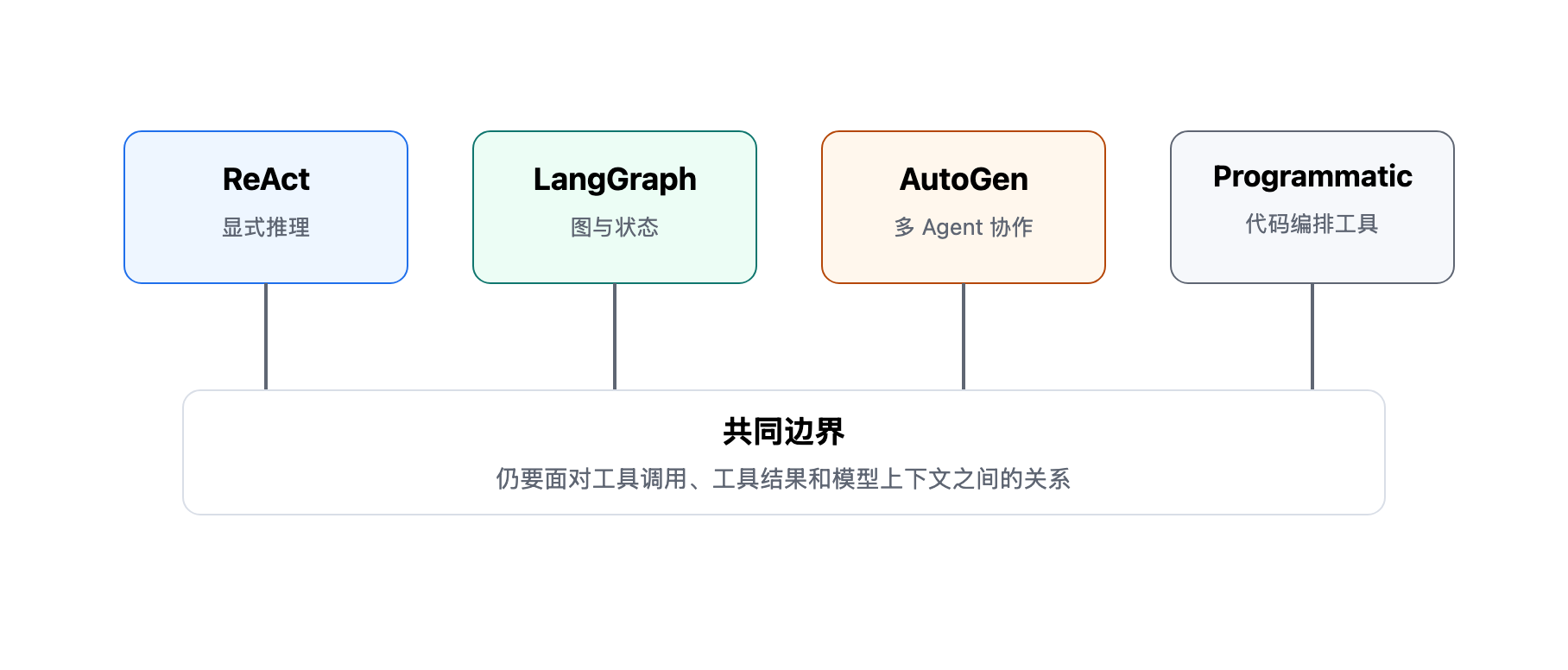
ReAct 的做法,是显式写出推理过程,把模型的中间判断暴露出来。模型不是直接丢出一个动作,而是先说明“我为什么要这么做”;等观察结果回来后,它可以检查前面的判断是否成立,再决定继续、换路,还是停下来。这种做法是有些帮助的,但是没有减少工具的调用次数,根本问题其实还在。
LangGraph 的做法,是把 Agent 执行过程显式建模成图。节点可以是模型调用、工具调用、人工审核或普通函数;边决定下一步走向;状态在图里流动;checkpoint 负责保存中间状态。这样一来,长任务可以暂停、恢复,也可以在关键步骤引入 human-in-the-loop。
不过,它主要解决的是“流程如何编排”和“状态如何持久化”,并不是冲着解决“工具结果应该如何变成干净观察”的问题。
AutoGen 的做法,是把单个 Agent 拆成多个会话角色。不同 Agent 可以扮演规划者、执行者、代码运行者、审核者,彼此通过消息协作;有些场景里还会有 group chat 或 manager 来协调多个 Agent 的发言顺序。这个做法也没有解决toolCall的问题:单个Agent仍然避免不了大量的工具调用。
Anthropic 的 Programmatic Tool Calling看起来效果最好:让模型写代码来编排多个工具,把中间结果留在代码执行环境里,只把最终结果返回给模型。但是每次都能编写代码来调用工具的场景是很有限的,效率也低,还是无法彻底解决问题。
可以看到,上面的这些方案想法都很好,也确实各自解决了一部分问题,但它们都无法绕开这个基本事实:模型和工具之间的核心交互仍然围绕 tool calling 展开。
因为它们的解法都漏掉了一点:模型和 runtime 的职责分工并没有根本变化。
根本原因:runtime 太被动
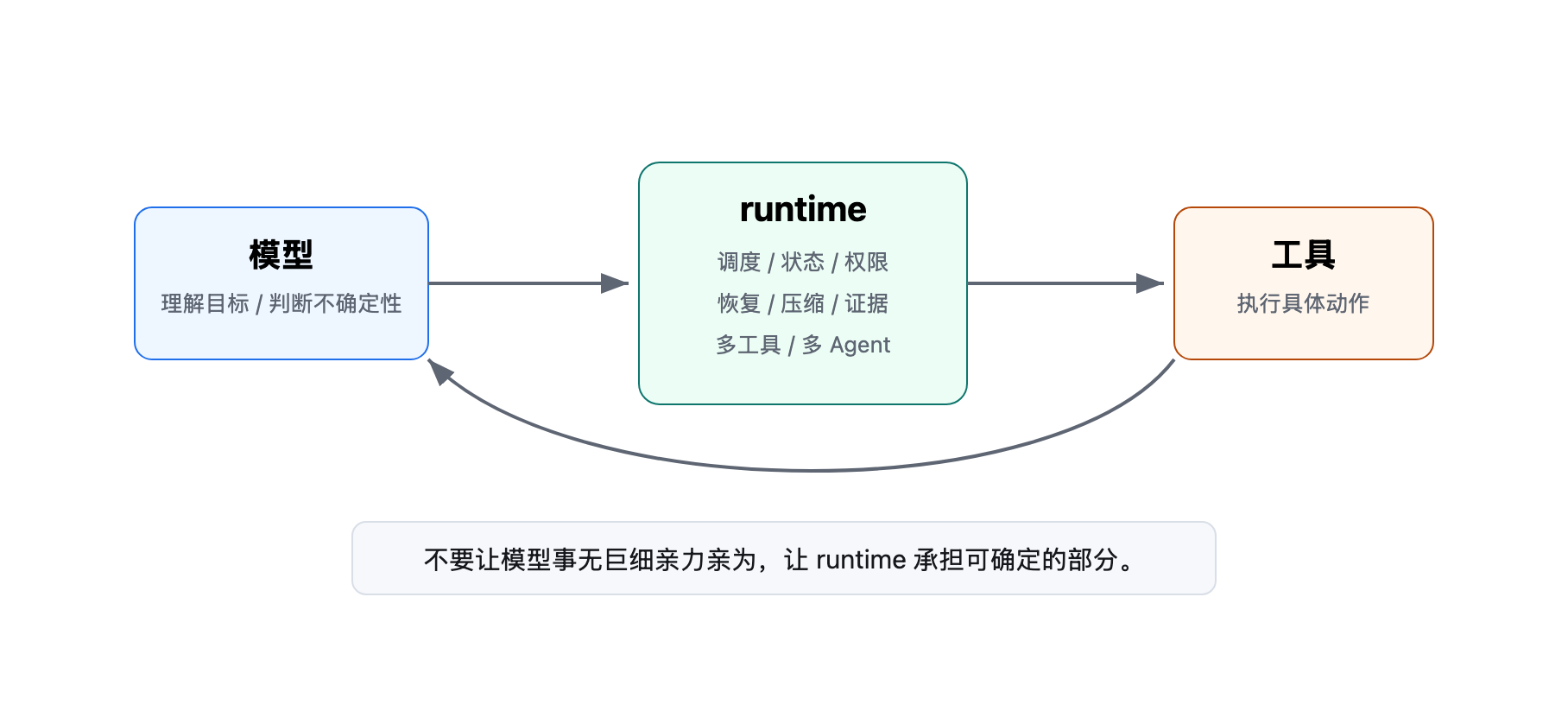
toolCall loop 的最大问题,不是不应该调用工具,而是不应该完全交由大模型,要给runtime也分配一些职责。
模型要决定下一步调用什么工具,要从结果里提炼重点,要记住任务状态,要判断是否重试,要决定什么时候结束,还要解释给用户听。
但是模型擅长的是理解目标、处理不确定性、生成解释,而执行、调度、存储、恢复、权限控制、状态管理等是runtime才擅长的。
为什么一切都要交给大模型呢?
不能因为模型聪明,就把所有事都交给它,聪明如诸葛亮,事无巨细亲力亲为也会累死在五丈原。
在现代的Agent的架构设计中,runtime几乎没有做多少事情,它的地位被大大低估了,它值得重新设计一次。
要优化以上问题,我们必须做好模型与runtime的分工,能交给确定性系统的,就不要交给模型临场处理,让runtime发挥更重要的作用,承担更多的职责。
为此,我为Agent设计了一套新的运行协议来替代toolCall。
这套协议重新定义了大模型的输出和请求大模型时的输入,减少了工具调用次数,也优化了大模型对每次请求的理解。
通过这套协议,我们允许大模型同时调用多个工具,甚至调用多个Agent,甚至乎,只告之runtime想达到的目标由runtime来决定怎么调用工具。
通过这套协议,可以让针对大模型的输入更加接近自然语言,更加容易让大模型理解,更适合推理。
欲知有关于这套协议的设计思路,欢迎跟我一起来探讨。
参考链接
- ReAct: Synergizing Reasoning and Acting in Language Models
- AWS Agentic AI Foundations: Perceive, reason, act
- Hugging Face Agents Course: Thought, Action, Observation
- LangChain Agents 文档
- LangGraph Overview
- LangGraph Persistence
- AutoGen: Multi-agent Conversation Framework
- Anthropic: Building effective agents
- OpenAI Function Calling 文档
- Anthropic: Introducing advanced tool use on the Claude Developer Platform
相关专题
常见问题
toolCall 为什么会拖慢 Agent?
因为每一次工具调用都会产生结果,结果又会回到模型上下文。任务越长,日志、搜索结果、文件片段和失败记录越多,模型要处理的噪音也越多。
减少 toolCall 次数就够了吗?
不够。调用次数只是一个指标,关键还在于工具结果如何被整理成模型可用的观察内容。原始输出少一点有帮助,但语义更清楚更重要。
Runtime 应该接管哪些职责?
Runtime 适合接管工具调度、状态保存、结果去重、观察整理、权限控制和证据记录。模型保留判断和解释职责。